Bayesian thinking and the nature of learning
Introduction
Let us image to ourselves the case of a person just brought forth into this world and left to collect from his observation of the order and course of events what powers and causes take place in it. The Sun would, probably, be the first object that would engage his attention; but after losing it the first night, he would be entirely ignorant whether he should ever see it again. He would therefore be in the condition of a person making a first experiment about an event entirely unknown to him. But let him see a second appearance or one return of the Sun, and an expectation would be raised in him of a second return, and he might know that there was an odds of 3 to 1 for some probability of this. This odds would increase, as before represented, with the number of returns to which he was witness. But no finite number of returns would be sufficient to produce absolute or physical certainty. For let it be supposed that he has seen it return at regular and stated intervals a million of times. The conclusions this would warrant would be such as follow — There would be the odds of the millionth power of 2, to one, that it was likely that it would return again at the end of the usual interval.
The example cited above is by Richard Price (1723 - 1791), a British preacher and mathematician, who was the literary executor of Thomas Bayes (1701 - 1761), the British statistician and Presbyterian minister. Richard was responsible for editing and publishing Bayes’ work after his death, one of which is the famous probability theory theorem bearing his name: Bayes’ theorem that first appeared in An Essay towards Solving a Problem in the Doctrine of Chances. The example I cited, also known as the sunrise problem, seek to answer the following question: Will the sun rise tomorrow ?
Amongst several great mathematicians, this question was given consideration by the French mathematician Pierre-Simon Laplace (1749-1827) in his book A philosophical essay on probabilities that was published in 1814. But for you, maybe it’s not the kind of questions that keeps you awake at night. Neither am I by the way. After all, it seems to happen every day without exception, and no history book has ever mentioned that some day, somehow, it did not. But more often than not, we encounter in our day to day life twisted versions of the said sunrise problem, in which we have to make decisions and figure out probabilities of some events occurring given a lack of information or a lack of experiences. Problems like these that arose very often lead us to reconsider our interpretation of the very concept of probabilities. Should we consider them as being a part of the world representing how frequently something will happen given an infinite number of trials ? Or should we interpret them as being degrees of belief or credences on events that may or may not occur ? Does Mother Nature have a say in the matter ? Did we evolve to look into the future in a certain way rather than in another ?
The Bayesian vs Frequentist debate
This is not a new debate. In fact, it’s been an academic argument, since the time of Bayes, that has sharply divided the sphere of probability theory on the very fundamental definition of probability itself. This has led to the creation of two main schools of thought: the frequentist vs the Bayesian. Frequentists define an event’s probability as the long-run expected frequency of occurrence. Thus, probabilities, from a frequentist perspective, can be found, in principle, by a repeatable objective process devoid of any subjective opinion. On the other hand, Bayesians interpret probabilities as being degrees of belief in events that may or may not occur. More specifically, a Bayesian will assign to every claim, belief, or hypothesis that may or may not be true, a prior credence. When new evidence comes in, this prior credence is re-weighted in order to obtain the posterior credence, which will subsequently become the next prior. Thus, under the Bayesian umbrella, no claim is perfect. Rather, it is a work in progress, always subject to further refinement and testing. Furthermore, it is perfectly OK to assign probabilities to non-repeatable events such as which candidate is more likely to win the next elections. Since the event is not repeatable, orthodox frequentists would have hard time computing such probabilities. That is, you can’t run the election cycle an infinite number of times and calculate the proportion of them that each candidate has won. However, the Bayesian will assign a degree of belief to each possible outcome, based on what information he has access to at the time of computing the said probabilities.
Bayes’ rule: quantifying uncertainty
The basic idea of Bayesian probability is that you update your beliefs in the light of new evidence. The whole purpose of science is to examine data in order to improve our certainty of the world, and the Bayesian framework sits at the heart of the scientific and critical way of thinking. Its core is honestly accepting the lack of knowledge. Technically speaking, it is expressed by giving no certain answers, ever. It always answers questions with probability distributions. With the help of Bayes’ theorem that puts this all together in a concise and elegant yet simple equation, the eventual purpose is to find the probability of causes by examining effects. Symbolically, this equation can be expressed as follows:
\[\underbrace{Pr(H|data)}_\text{Posterior belief} \propto \underbrace{Pr(data|H)}_\text{Likelihood of the data} \times \underbrace{Pr(H)}_\text{Prior belief}\]- The Prior probability is what we believe before we see any data.
-
The Likelihood is an answer to the question of how well does the hypothesis explain the data ?
- The Posterior probability is what we believe after we have seen the data.
In essence, Bayes’ theorem tells us that our belief in a given hypothesis after seeing the data is proportional (the $\propto$ sign) to how well that hypothesis explains the data times our initial belief. It also gives us a quantified way to update our belief system each time new data comes in. In fact, the resulting posterior will subsequently become our next prior, and this is how we improve our certainty of the world: by starting somewhere and examining data.
Another important point to note about Bayes’ rule is that all the hypotheses that may explain the data must be considered in the computation of the posterior. In fact, the formula I have presented earlier is a simplified version of Bayes’ rule to get the intuition behind it. The exact version is as follows:
\[Pr(H|data) = {Pr(data|H) \over \underbrace{\sum_{H^{'}} Pr(data|H') \times Pr(H')}_\text{All possible hypotheses}} \times Pr(H)\]In order to compute the posterior, we have added a denominator that takes into account all the possible hypotheses that may explain the data. An example may be needed in order to grasp the whole thing.
The Bayesian framework in action
Let’s consider the famous Black Swan example. Let’s assume we have seen $1000$ swans. $0$ of them were black, and $1000$ were white.
If we were to ask a frequentist about the probability of accidentally finding a black swan after this observation, his answer will be
\[\frac{\text{total number of Black Swans}}{\text{total number of Swans}}=\frac{0}{1000}=0\]Whereas the Bayesian’s answer will depend on his prior knowledge:
- If he was sure that there are no black swans a-priori; $Pr(\text{Black Swans exist})=0$, then this observation will simply confirm this fact
and he will end up with a posterior belief equal to zero as well.
\[Pr(\text{Black Swans exist}|data)=0=Pr(\text{Black Swans exist})\]-
However, if he knew for sure that there are certainly black swans a-priori; $Pr(\text{Black Swans exist})=1$, then the posterior belief will be:
\[Pr(\text{Black Swans exist}|data) = \frac{Pr(data|\text{Black Swans exist}) \times Pr(\text{Black Swans exist})}{[Pr(data|\text{Black Swans exist}) \times Pr(\text{Black Swans exist}) + \\ \quad Pr(data|\text{Black Swans DO NOT exist}) \times \underbrace{Pr(\text{Black Swans DO NOT exist})}_{=0}]}=1\]
Making his prior equal to one makes the probability of the remaining hypothesis equal to zero; $Pr(\text{Black Swans DO NOT exist})=0$. Thus, even if this observation highly contradicts his prior belief, it won’t change it one iota:
\[Pr(\text{Black Swans exist}|data) = 1 = Pr(\text{Black Swans exist})\]- Finally, if he starts from a prior guess other than zero or one, let’s say a $Pr(\text{Black Swans exist})=0.5$, then the posterior probability of finding a black swan after $1000$ negative attempts would be different from the prior probability. In fact, we can even compute this posterior’s exact value using Bayes’ rule, given that:
- The prior belief:
- The likelihood of the data given the prior belief being true:
Indeed, the observation shows that in $1000$ swans there are no Black ones, thus it does not confirm their existence. This is why this probability should be very low but not zero since this is the only observation that has been made and it may not be that conclusive to be that certain.
- The denominator, which is the likelihood of all possible hypotheses. There are two in total, that are: Black Swans either exist or not.
- At this stage, we are good to go to update the posterior belief:
Since Black Swans do exist in reality, the Bayesian is the winner in this case.
Do priors matter ?
Yes, they do. In the previous example of Black Swans, we have seen that depending on the Bayesian prior, we get different posterior beliefs. And in fact, this is how science works when it comes to understanding the real world. Everyone enters the game with some initial feeling about what propositions are plausible, and what ones seem relatively unlikely. However, the data collected from experiments will be used to update each one’s prior, thus moving everyone towards a common consensus. There is not a correct or an incorrect prior. Instead, there are some rules of thumb that help to better choose one’s starting point:
-
The first one is to avoid certainty in the absence of data. By certainty I mean assigning probabilities of one or zero to some hypothesis. If we start with a prior equal to zero or one, then the posterior will always be equal to the prior, as we have seen in the Black Swans example. Thus, all the interest of the Bayesian method will be lost, in the sense that our belief won’t be updated anymore, ever, and will always be equal to the initial prior. Consequently, if the initial prior in the absence of any data is wrong, which will always be the case, then we will always hold this wrong belief and we will be making dogmatic statements, regardless of any contrary evidence.
-
The second one is the use of Occam’s razor: simple hypotheses must be given larger priors than complicated ones. To illustrate this point, I have found that Sean Carroll has done a pretty good job explaining it very well in the following example, picked from his book The Big Picture (which is a great read that I recommend by the way):
Consider three competing theories. One says that the motion of planets and moons in the solar system is governed, at least to a pretty good approximation, by Isaac Newton’s theories of gravity and motion. Another says that Newtonian physics doesn’t apply at all, and that instead every celestial body has an angel assigned to it, and these angels guide the planets and moons in their motions through space, along paths that just coincidentally match those that Newton would have predicted. Most of us would probably think that the first theory is simpler than the second—you get the same predictions out, without needing to invoke vaguely defined angelic entities. But the third theory is that Newtonian gravity is responsible for the motions of everything in the solar system except for the moon, which is guided by an angel, and that angel simply chooses to follow the trajectory that would have been predicted by Newton. It is fairly uncontroversial to say that, whatever your opinion about the first two theories, the third theory is certainly less simple than either of them. It involves all of the machinery of both, without any discernible difference in empirical predictions. We are therefore justified in assigning it a very low prior credence.”
Since priors are subjective quantities, the frequentists refuse to include such notion into mathematically rigorous theory. This is true, in some extent. However, this subjectivity of priors is somewhat “compensated” by likelihoods which are assumed to be, and must be, objectively determined quantities. Everyone’s entitled to their own priors, but not to their own likelihoods. This way, in the light of new evidence and thanks to the objectivity of the likelihood function, we should move towards a common consensus, even if we had different starting points.
The Bayesian Brain Hypothesis
In interrogation rooms, when they would like to torture people, one of the reasons they would use electrocutions is because obviously it is a massively intense source of pain. But the catch is that they barely have to use it. They hit the guy a couple of times and then all they have to do is threaten. The brain of the guy being tortured has associated with electrocutions a prior of intense pain. He does not need to be electrocuted anymore, he is already hurt by his brain’s own prior.
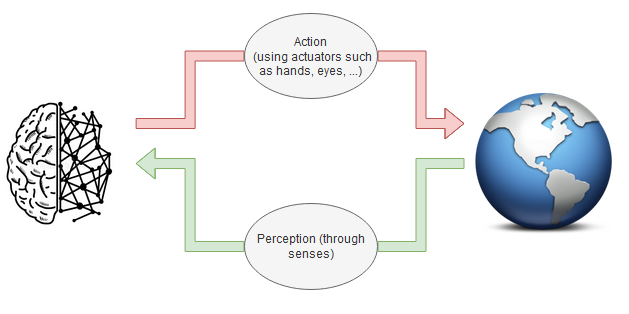
Figure 1: Brain-World interface. (Drawn using draw.io)
The traditional view of the brain sees it as a feature detector. It passively waits for signals to come to its sensory inputs, then these signals flow up a hierarchy to higher level layers to detect more complex features. For example, in the lower level layers of your visual cortex, the brain is sensitive to bars, and as you ascend the cortical hierarchy, these statistical features are being aggregated together to arrive to a complex percept. This is the view that has inspired the development of artificial neural networks, the building block of deep learning. Once in the highest area of the hierarchy, a feedback is sent, which can be seen as a modulation to try to correct the detection process. Whereas, recent breakthroughs in neuroscience and cognitive sciences suggest otherwise. They suggest what is called the active inference view of the brain. This active inference view flips the traditional view on its head. It says that, on one hand, the top-down-feedback-thing is what the brain is mainly engaged in, and can be seen as predictions of what a particular area of the brain should sense next. On the other hand, what flows up is the prediction error; the discrepancy between what was expected and what is actually sensed. Consequently, the brain is seen as a generative engine of models of the world. Its job is to figure out a good model; a model generating the minimum amount of prediction error. According to this framework, there is no prediction-free layer. At any layer, predictions occur and unexplained signals move upstream.
More specifically, the active inference method says that the neocortex; the top part of the brain, is comprised of ascending and descending pathways or (feed-forward and feedback pathways). The ascending pathways are conveying prediction errors or discrepancies between observations and expectations, at each level of the cortex hierarchy. Whereas the descending pathways convey those predictions. And according to Karl Friston, which is considered the greatest and most cited neuroscientist of the 21st century, with over 200,000 citations, and known for many influential ideas in brain imaging, neuroscience, and theoretical neurobiology, our brains act in a way that minimizes a statistical quantity called the Free Energy. Without digging into the mathematics behind this principle (maybe I will keep it for a later post), the brain is essentially seen as a hypothesis-testing mechanism, an inference engine, one that attempts to actively infer the real world and construct explanations for its own sampling of the world based on information it gathers from its sensory input. Its point is to mitigate surprises; unlikely events given its internal model. Basically, it says: “this is my prediction, and I will do everything to make it fit the observation”. When the hypothesis the brain is making matches the observation, that is when the Free Energy quantity is minimized.
How does the brain actually minimizes this prediction error ?
There are no but two ways of doing so. It either changes its internal model; tuning it so that the next prediction fits the observation, or changes the world, by taking action, to better fit the prediction the internal model is making.
Where and when do Bayes comes into play ?
We have seen earlier that Bayes’ rule is a just a way to combine a prior probability with a likelihood to get a posterior probability.
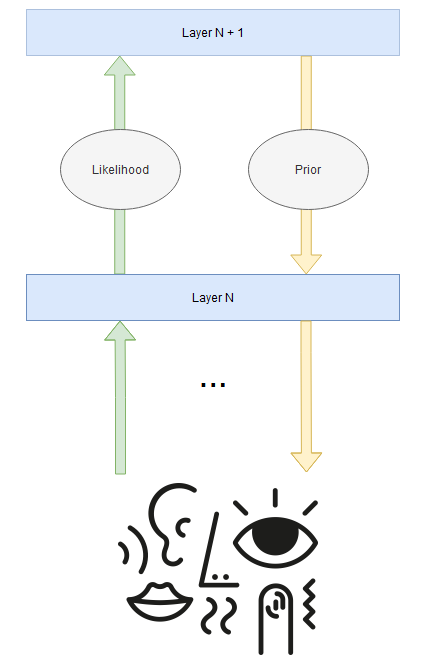
Figure 2: Bayesian bootstrapping. (Drawn using draw.io)
At each layer, the descending connections carry priors in the form of neural predictions based on the internal model and the ascending connections integrate the data that has just come in in the form of unexplained prediction errors. Bayes’ rule is just the optimal way to combine these two signals, resulting in a posterior probability, which will subsequently become the next prior. This real-time process, called Bayesian Bootstrapping, continues ad infinitum.
To sum it all up, the brain is always trying to justify the stories it is making up. Its job is to mitigate surprises (by minimizing the Free Energy), either by tuning its model or acting in the world to change the observation. It starts with a prior on the hidden states of the world that may have caused its sensory input. Then, once new data is collected, it adjusts its prior accordingly.
Conclusion
Is our brain truly Bayesian ? Saying that the brain uses Bayes’ rule to compute the posterior is a bit of an exaggeration, isn’t it ? After all, the cortical homunculus sitting on the top of the brain does not have just that to deal with, does he ? Furthermore, when the hypotheses’ space is very large, which is always the case in real world situations, the denominator of Bayes’ rule becomes computationally totally intractable. This does not align with the fact that the brain operates under limited neural resources of power, time, memory, etc.. Additionally, this view contradicts the Darwinian view point of the brain. In fact, the aim of evolution through natural selection is not to make the brain an optimal learner that uses such highly efficient and rigorous even optimal methods, but has “designed” it just to be “good enough” to survive. So yes, the brain is not updating its beliefs according to the exact formulation of Bayes’ rule, but rather some variations and approximations of this rule. And in fact, this is what it has been shown through several experiments. The brain does approximate the Bayes’ rule. In a later post, I will go on the mathematics behind such approximations, especially one that has attracted too much attention lately, which is the Free Energy Principle of Karl Friston.
And in response to the question laid out in the introduction.. yeah we are pretty sure that the sun will rise tomorrow, and if it does not, then we will update our beliefs accordingly… Well if we are still around.
References and further reading
The thermodynamics of free will
The Bayesian Brain: An Introduction to Predictive Processing
The history of the future of the Bayesian brain
The free-energy principle: a rough guide to the brain?